- Business Collaboration
- Business Collaboration talk
- Abstract/Contents
1 Introduction
2 Review
3 Web Collaboration Software
4 Design > Test
5 Conclusion
6 Glossary
7 Appendix
8 References
This is an archived version, please use the menu on the left, or jump to the new version: 4.00 Design through to testing
4.1 Design
The design approach chosen for developing the engine to drive "Co-operative authoring and collaboration over the Web" was the Spiral design model [Pressman 1992].
"A model of the software development process in which the constituent activities, typically requirements analysis, preliminary and detailed design, coding, integration, and testing, are performed iteratively until the software is complete." Source: IEEE Std. 610.12-1990.
The YEdit system was created using the spiral design model, which involves incremental development, iterating through the cycle, starting with the ideas, design, through to the coding and testing. Each time through this cycle increases the functionality, usefulness and completeness of the application. Inevitably the application is refactored (Refactoring is the process of changing a software system in such a way that it does not alter the external behaviour of the code yet improves its internal structure [Fowler 1999]) as it increases in size (this refactoring is an essential part of the process, otherwise the complexity would increase to a point that would not be manageable, and prior to that, it would become very difficult to continue).
This model has advantages over other models when designing applications in new areas. Unlike the Waterfall model, this model allows the high level design to change, as and when is needed, and also allows the design to flow both ways (that is, for discoveries during design, coding, and testing to be applied to the next round of the design), as new approaches are found to problems. As new ways of doing things are found, they are fed back into the loop as it goes around again. This allows new ideas to permeate back up through the design to the top level, and every so often these adjustments will lead to a large refactoring of the whole application. This refactoring decreases the complexity, and because the design has been flowing both up and down the application, a full refactoring is possible (and desirable) to do. In the Waterfall model, this would be much more difficult (generally the Waterfall model is best for applications for which you already have many of the building blocks). The Spiral model is useful if you need to create the building blocks, as you are creating the application.
The spiral approach is better for new designs where the emphasis is on the creative dimension of the development. The iterative approach with the Spiral model is all the more important when embarking on a novel type of project with a reasonable understanding of its overall design, but no clear idea of the details of its components. The iterative approach allows new ideas to be tried, and changes can be made in approach as new information comes to light. This is also important for the free flowing web of information because over the time that this has been created, new ideas about the system have surfaced (such as integration into word processors) and other methods of access have arisen (such as access via handheld computers, with much smaller screens, and access via WAP). The reason that an iterative approach is important is that the Internet is a fast moving area, and this design will need to be able to adapt readily to any new surroundings. The spiral model approach allows you to concentrate on the big issues first, solve them, and go through the process (which includes the full range of software engineering, from ideas, design, right through to testing and feedback). At this point the whole process is repeated. Each iteration gives a finer resolution than the previous, and solutions can be found to unexpected problems. In fact, the three level design of the engine (user interface, middle interface, server interface) came from a refactoring of the code. This particular refactoring opened the way to splitting the user and server sides of the engine completely apart, as originally the user and server interfaces had a much higher integration.
Another reason that the spiral model was a good choice for this design was because the process that was undertaken started with just a broad idea. That was, to look at the Web and see how communication over the Web could be enhanced. In the process, several different areas were considered as possibly contributing to better communication over the Web, such as Web themes and multi-tier web sites. Possible ideas that could help communication over the Web were looked at in the early stages of this project, and one was incorporated into the final "Co-operative authoring and collaboration over the World Wide Web". These ideas were important to look at, as at that early stage, it was not entirely clear what area of improved communication over the Web would be the one that would be best suited to this thesis. The two main areas that were considered before settling on co-operative authoring and collaboration were web themes (similar to CSSs, but on the server side and more of a content/context split, rather than just enhanced display), and multi-tier/multi-homed web sites (to allow much more redundancy in case of problems), the main points of which were incorporated into this research.
Web Themes
Web themes apply styles/themes to web pages on the server side, allowing one web page to contain content, while using web themes to define the context. That is, all the content would be in one file, which simplifies the process of updating that information, while the web page contains pointers to the context information (like buttons, banners and other non-content information). These pointers retrieve the appropriate version of the context for the user, whether it is text only, or full graphics. Below (Figure 2: Example web page for Web themes) is an example of what the web page looks like on the server side. Each of the <SERVLET> code tags is replaced by the output of the servlet. The servlets retrieve the appropriate information from a database (part of which is repeated below in Figure 3: Example of the Web theme data), and return it as the output.
<HTML><HEAD> <TITLE>Web Themes Test sheet</TITLE> </HEAD>
<SERVLET CODE="theme"> <PARAM NAME="HTML" VALUE="Body"> <body>Your web server has not been configured to support servlet tags. </SERVLET>
<a href= "about/"><SERVLET CODE="theme"> <PARAM NAME="HTML" VALUE="About Us"> About Us </SERVLET></a>
<a href= "Catalogue/"><SERVLET CODE="theme"> <PARAM NAME="HTML" VALUE="Catalogue"> Catalogue </SERVLET></a>
<a href= "comingsoon/"><SERVLET CODE="theme"> <PARAM NAME="HTML" VALUE="Coming Soon"> Coming Soon </SERVLET></a>
<!-- Note: The text between the <PARAM> and the </SERVLET> tags is not really needed, as once the server is running correctly, they will never be seen (as it does not rely on the browser, like applets. They are present only for completeness. -->
</BODY></HTML>
Figure 2: Example web page for Web themes
| Theme |
ID |
HTML |
|---|---|---|
Text |
Body |
<body> |
Text |
About Us |
About Us |
Text |
Catalogue |
Catalogue |
Text |
Coming Soon |
Coming Soon |
Graphics |
Body |
<body background= "/images/background.gif"> |
Graphics |
About Us |
<img src="/images/about_us.gif" width="90" height="20" border="0"> |
Graphics |
Catalogue |
<img src="/images/catalogue.gif" width="90" height="20" border="0"> |
Graphics |
Coming Soon |
<img src="/images/coming_soon.gif" width="90" height="20" border="0"> |
Figure 3: Example of the Web theme data
Web themes were looked at as a possible help for web sites that maintain multiple versions of pages, each supporting different options, such as text only pages, and graphical pages. This is quite an important thing to do because not all web browsers support all of the latest display options (for example, graphics, sound, non-HTML formats, etc). Effectively web themes split the content of a web site from the context, which means that there is only one copy of the content to keep up to date, as when multiple copies are used, it can become difficult to keep all of them up to date with each other. The web themes engine used SSI (Server Side Includes) in the first prototype, and Java servlets in a later prototype to include the activate content into the web page. This would then fetch the appropriate information from a database and return it to the web browser, thereby allowing one source document to be viewed in several ways, so text and graphical versions of the page, or any other type, could all be created from the same content.
Although the idea was to split the content from the context, if the pages were interpreted instead of including dynamic content, it would be possible to layer both the content and context. Then it would be possible to create templates for all of the pages on a site, and create pages recursively on the fly by allowing inclusion of sub-site templates for different layout of different sub-sites. For example, there may be one template that controls the overall look of the whole web site, which includes content and context from other authors. Each author's content and context could contain versions for each output type they want to support, which can be repeated recursively for larger sites that have many levels between the full web site layout and the individual authors of each page. This would mean that each document may contain content and context from several different authors, all custom built for the person that is currently viewing the document, but there is only one set of content to keep up to date. It also has the side effect of allowing authors to delegate specific portions of a document to others, while maintaining the overall feel of their portion.
It was decided to leave the idea of web themes at the second prototype stage because there were others with similar ideas at the time (circa 1998), and because ideas were looking promising to follow with regard to research on co-operative authoring and collaboration. Today there are options for using XML (http://www.w3.org/XML/) and transformational XSL (http://www.w3.org/Style/XSL/), or JSP (http://java.sun.com/products/jsp/) with XML or HTML.
Multi-tiered/Multi-homed web sites
There was some investigation into multi-tiered/multi-homed web sites (some of which is incorporated into co-operative authoring). Multi-tiered/multi-homed web sites are those that use redundancy, in this case, redundancy of information to achieve better performance and/or better reliability. A multi-tiered web site splits different tasks (for example displaying the static site and displaying the dynamic site) off to different web servers, which may be on the same machine, or on other machines. This allows the most requested content to be redundantly available, while keeping the advantages of both the static and dynamic sites. Splitting tasks in this manner allows a better load-balancing scheme, which means faster response to user queries, and higher reliability, because if one component fails, it is much less lightly to cause the rest to fail.
A multi-homed server takes this to another level. With a multi-homed server, not only is each task split off to a new web server, but also each web server is in a separate location, possibly with different bandwidth connections. This may not make much sense if the server tasks are mutually dependent - if, for example one is serving the text of a page, and the other the images. If, on the other hand, the servers are performing independent tasks - say one server is set up to allow documents to be read, and the other is set up to allow those documents to be edited - then if one of the servers (or connections to the server), is disrupted, the functions provided by the other server are still available.
A multi-tiered/multi-homed web site would probably be more complex than would be required for some web sites, but for anyone who depends on the reliability of their web site (or web site connection), this could be vital.
After investigating the possibility of doing research along the lines of multi-homed/multi-tiered web sites, it was decided to concentrate instead on co-operative authoring and collaboration, but use some of the knowledge gained from multi-homed/multi-tiered web sites in the co-operative authoring and collaboration research.
Recently a company called Akamai Technologies Inc (http://www.akamai.com/) started to deliver a product that is similar to the system described above, using a massive distributed network of web servers. Akamai's aim is to "deliver a better Internet", by linking you to the nearest copy of the web site, thereby providing faster and more reliable results.
Co-operative authoring and collaboration
Out of the exploration of the origins of the Web, and the exploration of web themes and multi-tier web sites, came the idea to work on the area of web collaboration. The idea of web collaboration sparked some interest because it seemed to be an area that had not had much work done on it since the Web was commercialised. The idea of Web collaboration had some of its roots back in the original ideas for the Web, as well as paper based document creation, and it has the potential to be a very useful contribution to the Internet community.
The ideas about collaboration were coloured by the fact that there are many options for collaboration already available over the Internet. Options for collaboration over the Internet include using IRC to talk (or type) interactively, email and Usenet for less immediate communications, and web pages for demonstrations and the like, these are just a few of the possibilities. These options meant that the ideas for collaboration over the Web had to be refined further than just collaboration. The ideas were refined through to collaboration on particular documents, or in other words, more along the lines of co-operative authoring, rather than the support role that these other methods of communication provide.
BSCW / CSCW
As work was proceeding on YEdit, CSCW (Computer Supported Co-operative Work) and BSCW (Basic Support for Co-operative Work) were discovered. BSCW enables collaboration over the Web and is a 'shared workspace' system that supports storage and retrieval of documents and sharing information within a group. This is integrated with an event notification and group management mechanism in order to provide all users with awareness of others activities in the shared workspace. In particular BSCW is a networked support mechanism, which provides support for co-operative document creation, (for example threaded discussions, group management, search features, and more) and therefore would make a good fit (if the other methods of support are either not appropriate, or alternatives are looked for) with co-operative authoring over the Web.
WebDAV
Another project that was discovered was WebDAV [RFC2518]. Their goal (from their charter) is to "define the HTTP extensions necessary to enable distributed web authoring tools to be broadly interoperable, while supporting user needs". Again, as in the case of BSCW, this project is looking at a different area from collaborative authoring. In particular, the authors are defining a protocol for use by software to connect over the Web. The protocol includes some information that will be helpful for distributed authoring and versioning. It is very possible that in the future, any Web communication could use this protocol to communicate authoring and versioning information. WebDAV is a protocol, more specifically, it is an extension of HTTP/1.1, which adds new HTTP methods and headers to the HTTP protocol, as well as how to format the request headers and bodies. The headers that it current adds are locking (long duration shared/exclusive locking), properties (XML metadata, that is, information about the data), and namespace manipulation (for move and copy operations and for collections, that are similar to file directories). Several extensions are planned, such as advanced collections (which adds support for ordered collections and symbolic links), versioning and configuration management (which adds headers for operations such as history lists, check ins and check outs, both at the individual object level and the collection level), and access control (for controlling access to resources).
The YEdit system that is being created in this research has the capability to be combined with BSCW and CSCW systems to enhance the abilities of both and the potential is there for that, but at this stage there are no plans to combine them. Also YEdit has the potential to use the WebDAV protocol to communicate from clients to the web servers. In the future, when the versioning part of the WebDAV protocol is decided on, YEdit will support it to enable other applications to access YEdit.
The YEdit engine has been created in Java using a combination of JBuilder (versions 2-3.5) and a standard notepad program. It has been tested on a few test systems, three systems running Red Hat Linux (versions 4.x - 6.2) running Apache (versions 1.2 - 1.3) with Apache JServ (versions 0.9 - 1.0), one of which started with the earlier versions of the software and was upgraded, the other two started with the later versions. Two were running Windows 95 for testing. The test systems were used to test ideas and code to check that it worked properly before it was uploaded to the main server at http://www.YEdit.com/ which is running FreeBSD 2.2.8-RELEASE, Apache 1.3.9 with Apache JServ 1.0.
4.1.1 Web-based access
The engine that has been created as part of this research is currently primarily set up to work over the Web, but it is not restricted to serving HTML pages. It allows for both the user access and the storage methods to be specified in the initialisation file, along with the name of the class that implements the functionality to either access the storage system, or display the results. Due to the design, this engine is not limited to serving web pages over the Web; it can serve any type of page (be it text, graphics, or other), from any storage system that an interface is created for. At present the engine assumes that pages are HTML text, but that is only a design decision to ease the testing. To allow any type of page to be stored (graphics, or other), a there are a small number of lines in the source code that need to be replaced with code that determines the content type from the file, rather than assuming that it is HTML.
Web-based access is currently the main method of accessing this engine, allowing pages to be created, edited, and deleted (that is, replaced with a blank page; the old versions are still present). An author can currently create pages with any content, although in the future code that is inserted may be screened for malicious content. The design of the engine is such that pages should be no different from any other general web pages, that is, they should look and act in the same way as any other normal web page. Because of this, web sites that implement this engine should look no different from any other web site that does not implement this engine, at least as far as people who are just browsing. This has important implications in terms of ease of use (there should be no learning curve needed to just browse the pages), and ease of access (anyone or anything, such as web spiders, should have easy non-impeded access to all pages that are available to the general public).
As well as being accessible via any access method (once an interface is created), the engine can also access any type of file storage system. At present the only one supported is a straight file system, but the support is present to allow access to any file storage system, with the creation of some interface code to the system. Probably the next file storage system interface to be created will be one to access a database. This will allow pages to be stored in a database, rather than in the raw file system as is done at the moment. Another useful storage system interface would be one to access a CVS system, which automatically takes care of versioning information, rather than the current system where the servlet records all the versioning information.
4.2 Design of the engine
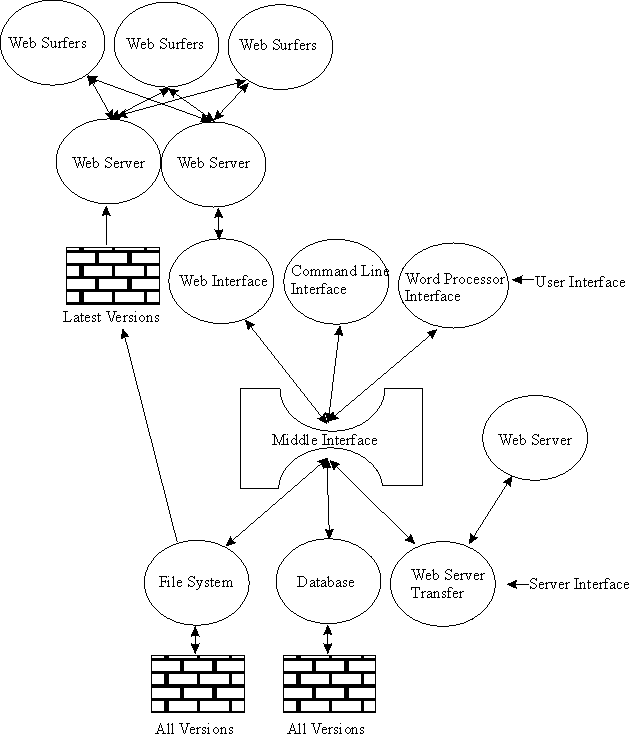
Figure 4: Interaction of the main components of YEdit
The YEdit system is composed of the components in "Figure 4: Interaction of the main components of YEdit". The main components are the "User Interface", the "Middle Interface", and the "Server Interface". Each of these interfaces will be discussed in the following section. As can be seen from the figure, the Web interface is just one of several possible methods of interacting with this system, two other methods of interacting will be using standalone programs, both GUI and command line, and directly with word processors. The same flexibility is contained in the server interface, with the ability to access other storage options such as CVS repositories, or databases.
The User interface
The user interface is the interface that people see and interact with. The ideal user interface is one that does not get in the way of the user using it. The user understands it intuitively, so that the user interface allows work to be done, without intruding on the user's experience of the site.
The main objectives for the user interface are to translate the requests from the user into requests for the "middle interface" (which is located between the user interface and the server interface, and acts as a middleman between them), and to return results from the middle interface to the user.
The Web user interface (as shown in Figure 5: The Web Interface servlets) has three main components. Those components are the read servlet, the browse servlet and the edit servlet, along with a couple of support servlets that are not directly required for using the engine (such as the user preference servlet and the survey servlet).

Figure 5: The Web Interface servlets
The Web user interface has been designed to interact over the Web, and works in conjunction with a web server to interface to the user's web browser. This allows access to the engine from any system that supports a web browser. The user interface talks with the web server using the CGI (http://www.w3.org/CGI/) protocol, which defines the interactions between the web server and the web server application. There is a servlet API that abstracts some of the CGI protocol, which makes the interaction easier, but it is still based on the CGI protocol, so knowledge of it is required for the creation of Java Servlets.
In the future, there can be other user interfaces to interact with via means other than the Web. For example there may be direct links into applications, such as word processors, integration into mobile computing, such as Palms and web enabled phones, or direct links to other types of application.
The read servlet is the most transparent of all the servlets to the user. The user accesses web pages through the read servlet, as if they were real static documents available from the web server, with just the name of the servlet before the request. For example the URL to access the web page "/scratch/" (or "/scratch/index.html") would be: http://www.YEdit.com/servlets/Read/scratch/ (or http://www.YEdit.com/servlets/Read/scratch/index.html). This activates the servlet "Read" in the "/servlets" directory of the server "http://www.YEdit.com/".
When the web server receives this request (assuming the web server accesses servlets through the "/servlets" directory, and there is a "Read" servlet present in the servlet directory), it passes the request through the servlet engine, to the servlet (or servlet alias) that is called "Read". From here, if the servlet has not been started (or if the servlet has changed since it was last called), it is loaded/reloaded and initialised, and then the request is passed on to it. The servlet looks at the parameters that it has been called with (one of which is the path information, that contains the string "/scratch/" or "/scratch/index.html"), and then works out the name of the file that it needs to read in order to satisfy this request. The servlet looks up any path information that needs to be pre-pended to the path information that was passed when the servlet was run, and constructs the full path for the file to be accessed (and adds "index.html" to the end, if the requested path is a directory). The servlet then creates an object that points to this file (whether it is in the file system, a database, or elsewhere). This object has been named for the sake of convenience an USL. An USL (Universal Stream Locator) is a name that has been given to an object that provides information on how to locate a source of information, such as a database, a file, a web page, etc. It is similar to an URL, but can contain any information to access an object, is completely system independent, does not rely on the pointing information being a string, and does not assume any particular method of access. The USL is then passed to the middle interface, which locates and returns the correct class to access the file (currently based on the initialisation file), and then uses that class to access the file and to read the latest version of the file. The read servlet then returns the web page to the user, as if it had been accessed directly. In the future, the read servlet may not be required, as when the edit servlet updates a file, it may also store the file in a directory that is directly accessible by the web server, thereby removing most of the need for a read servlet.
![]()
Figure 6: The toolbar that appears at the top of the document in Browse mode
The browse servlet is the one that people interact with when they are looking either for information about the web page (who the author of a particular version was, what a previous version looked like, when it was changed), or are interested in editing a web page. The browse servlet works much like the read servlet does, in terms of accessing a document. The browse servlet adds functions that are not available to users who are just reading the web pages, by adding a toolbar (Figure 6: The toolbar that appears at the top of the document in Browse mode) at the top of the document. The current set of information that this toolbar contains is the current version number of the document and this version's author. There are links to access other versions of the document, to jump straight to other web pages, and if this is the most recent version, then a link to edit this page also appears. If the page does not yet exist, a link is included to add the page.
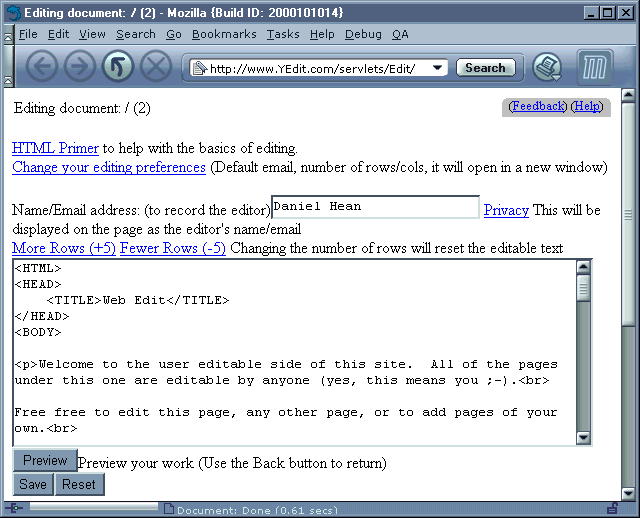
Figure 7: The edit screen
The edit servlet allows people to edit the web pages. It displays a page like the one in Figure 7: The edit screen. At present it returns a web page with various links and text areas for the author's name or email address and the text of the web page. There is also a quick survey at the bottom that requests information about how they find the site. There are links to the user's preferences (email, width and height of text area to edit in), help for HTML editing and links to make the text box for editing larger or smaller.
Users can set a flag by visiting and filling in the user preference web page (that allows people to set up their name or email as their identification, along with the preferred size for the text editing box). This means that when they later edit a web page, the text box containing the HTML will be the size that they set, and their identification will already be filled in (it can be changed at that point if required).
At the moment, anyone editing a page needs to have some knowledge of HTML, as the edit servlet displays HTML in an editable text box. This is a disadvantage to those that do not know HTML, although for some who know a bit about HTML, but not a lot, they could cut and paste between the text box and an HTML editor, but this does not help those that do not know any HTML. This design allows the ability to fully edit every page, while leaving the possibilities for future enhancement by using other methods (for example WebDAV).
After editing the page, the user can use the "Preview" button that is located underneath the text box to preview what the page will look like when saved. If the preview is satisfactory, they can use the back button to return to the edit page, and can then use the "Save" button to save their work. If their work saves correctly, they will receive a screen that gives them the option to either go back to browsing, or to go back to reading the web pages. If the save did not work, a reason will be displayed. If the save failed because someone else had edited (and saved) the document in the meantime, a page with both users' changes will be displayed. The changes can then be transferred to the current version, and resaved.
When the edit servlet receives a request, it loads the document, just like the read and browse servlets do. Once the document has been loaded, it displays the screen shown in Figure 7: The edit screen, with information to help editing (for example links to HTML help, user preferences, etc), as well as a text box for the editor's name, and a text box that displays the raw HTML of the web page that is being edited.
When the user has finished editing, or just wants to see what the current changes look like, they can press the "Preview" button. When the "Preview" button is pressed, the text that has been entered into the text box is taken and reformatted as a web page and sent back, as the new web page. To go back to editing, the user needs to press the "Back" button on their browser. One very important thing to note, is that the edit servlet must ensure that the edit page is cached, otherwise, when the user previews their work, all changes to the page will be lost when they go back to the edit page (using the "Back" button). The only thing the "Preview" button does is to display the changes to the user, it does not save anything on the web server, and therefore it is important that the user does go back and save their work.
Once the user presses the "Save" button, the edit servlet tries to save the changes that the user has made. It uses the class that was retrieved when the document was loaded, and uses it to save the document. In the process of saving, the version numbers are checked, to ensure that the version being saved is still the most recent version. If the version being saved is the most recent version, then it is saved, increasing the version number, and returning to the user a screen saying that the save succeeded, and giving them the option to either continue browsing, or to continue reading. If the save did not succeed, then the user is given an explanation. If the save failed because the document had been updated by someone else in-between the time that the current user started to edit, and saved it, then they are given the option to make the same changes to the new document. This is achieved by displaying a similar screen as to the normal edit screen, but with the changes that they made (that were not saved), as an extra text box on the screen. This allows them to copy the appropriate changes back into the current version, and to then save it.
The Middle interface
The middle interface defines the access that the user interface has to the underlying system. The reason for having a middle interface is to allow the user and server interfaces to be as decoupled as possible, allowing either or both the user and server interfaces to be changed, or replaced. This means that the user interface has no knowledge (and no need for knowledge) of the server interface, where, or how the files are being stored. Also the server interface has no knowledge (and no need for knowledge) of the user interface, where or how the files are being displayed and edited.
This split allows the engine to be used to store any type of document (web page, word processed document, etc), in any kind of storage system (the normal file system, a database, another web site, etc), using any kind of display, or user, interface (web site, command line, word processor). This means that the engine can be used for much more than the storage of web pages, and can in fact be used for all manner of documents that require co-operative authoring and collaboration to work on, which includes versioning. Because of the design of this engine, both user and server interfaces can be written to seamlessly integrate the benefits of co-operative authoring and collaboration into legacy applications that may not fully support co-operative authoring at present, such as web sites.
The middle interface specifies the actions that are available to the user interface to manipulate documents, for example loading and saving, version and author information. While the middle interface provides a selection of methods to the user interface to manipulate documents, it requires certain methods to be present in the server interface to provide the functionality to complete the user interface's requests. Not all methods that the middle interface supports need to be present in the server interface, as some of the methods provided are supplied in the middle interface, using other lower-level methods in the server interface.
The Server interface
The server interface is the interface to the file storage system (whether it is the normal file system, a database, or other versioning repository) that stores the information that is passed through the middle interface. Because the server interface is only accessed through the middle interface, this allows any server storage to be used, and/or interchanged at will, with no visible change to the users, and allows new storage options to be used as and when they become available. Because all access comes through the middle interface, all file storage systems should be compatible with each other.
The server interface has a specific set of methods that it must define and for which it must return the appropriate result, but not all methods that the middle interface supports need to be provided. This is because the middle interface has a default set of actions for specific methods that use the lower-level methods that are supplied by the server interface. There are some methods available in the middle interface that do not need to be implemented if their functionality is not required. There are also some that have default functionality, but should be extended by the server interface to allow the full range of responses, provided that the file storage system can supply the appropriate results.
The rest of the engine
Those interfaces (described in the preceding three sections, the user, middle, and sever interfaces) do the majority of the work in the servlet application. There are other servlets that help these three, and enable other features such as error logging and survey responses.
The Preference servlet looks after all the preferences and options for the system. This stores the information about the server, such as the name of the static and dynamic web sites, directory locations, and file names. This preference file is first looked for by the servlet in the location that the servlet is being run from, and then the home directory for the user and finally the main Java home directory. The preference file is loaded each time the servlet is loaded or reloaded.
The USL part of the engine is a replacement for URLs, mainly based on the fact that the information sources that can be used by the engine are not limited to normal files and web sites that can be normally accessed be a URL.
The utility classes include the logging and debugging class that makes it easier to locate and fix problems by directing specific debugging information to a specified place.
4.2.1 Java Servlets
The YEdit engine is written in Java utilising the server side technology of Servlets [Servlets] (Java Servlets are Java applications that run on a web server. They are similar to other CGI web server applications). There are many languages that could have been chosen for implementing the engine on the server side, but Java Servlets had the best match between the requirements of YEdit system (which are that the system be relatively simple to extend, can be extended on the fly, efficient for multiple uses of the system at once, and is portable to different operating systems), the programming language, and my knowledge of different programming languages at the time.
Some of the main reasons for choosing Java for the engine were because the programming language:
* is simple (compared with languages such as C++), as it omits some of the less understood and confusing features.
* is object oriented (an object is defined as "an entity that has state; is characterised by the actions that it suffers and that it requires of other objects; is an instance of some class; is denoted by a name; has restricted visibility of and by other objects; may be viewed either by its specification or by its implementation" [Booch 1986]).
* is dynamic, which allows new classes to be created and loaded at run time.
* has networking built in, so connections over the network (Web and otherwise), are much simpler to use than some other languages, no extra code is needed
* is robust. It is much more likely that if there is an error, it will show itself. Add to this garbage collection and memory management, which improve the robustness of the applications and means that errors are less likely to occur in those areas.
* is portable and architecture neutral, which means that once the code is written, it will work on any operating system or machine that supports the Java Virtual Machine (which is potentially most machines, from watches, fridges, phones, etc, as well as conventional computers, whatever operating system they use)
* is multi-threaded, so that more than one request can be run at the same time. This allows much better performance than a single thread, especially when each thread may not be at full working capacity the whole time (for example, when waiting for a file to load or save). This means that more people can use the server at a time
* with respect to servlets, has persistence, that is, once the overhead of loading the servlet is completed, it does not need to be repeated unless one of the classes is auto-reloaded because the class file has been updated
4.3 Current progress
A fully working prototype of the YEdit engine has been created and is available to everyone world wide through http://www.YEdit.com/. This prototype works by implementing one version of both the server and the user interfaces. The user interface is a web-based interface that allows anyone with a web browser to access both the information about this research and the prototype in which they can create and edit web pages. This is achieved using the three user interface servlets, the read, browse and edit servlets, to access and manipulate the documents that are stored in the file storage system. The middle interface has all of the functions that are required for the prototype. The middle interface can load (at run time), any server interface that is specified in the initialisation file. The server interface controls the file storage system that is used. For the prototype, the file storage system that is being used is the normal system file system, of the particular operating system that the engine is being run on (at this stage this has included both Unix and Windows). Because a normal file system does not support the full range of versioning and locks for editing specific versions, this is implemented by the servlet.
The current web site has been designed specifically to house this engine, and it has some information about it and how to use it (for example help on the different ways of accessing the documents, reading, browsing, editing, and some pointers to help for HTML). It houses the prototype and allows anyone to access it to try it out. The feedback that I have received from people who have responded about the web site and the engine has been positive. They seem to be interested in the usefulness of the engine, both in terms of the current use on the web site http://www.YEdit.com/, and the future use on other web sites.
The engine has been designed to move as many arbitrary limitations such as types of files or edit applications that are supported as possible from either the middle or the server interfaces, to the design of the user interface that accesses the engine. This allows the creator of the user interface to support any and all types of documents. In principle the engine can handle any type of document with complete transparency. This potentially also includes streaming media (a sequence of video and/or audio that is sent in a compressed form over a network and is decoded and displayed as it arrives, rather than the traditional method of downloading the whole clip, and then viewing it).
The engine has been written in Java because the main considerations of this engine match the strengths of Java. Some of these strengths are the network ability, the robustness and portable nature of Java, and especially servlet persistence in web servers, and the cross-platform write-once, run-anywhere ability. The write-once, run-anywhere ability will by itself ease the maintenance of the engine.
4.4 Testing
Testing [Whittaker 2000] has taken place throughout the whole time that the engine has been in the process of being created. This includes tests to see what could possibly be done, testing individual components of the engine one at a time, thorough to testing each servlet and finally the testing of the whole engine.
Testing of the components involved creating test cases and wrappers for the code to simulate the inputs that would be expected, and to check that the outputs were reasonable. For example, as part of the testing of the file system server interface, the first things that were tested were that the code was receiving the correct information, and decoding it correctly. This involved extracting the path information from the request, extracting the location of the files on disk, the combination of that information, and checking all the way through to make sure that the file system server interface had decoded the information correctly. Once that was tested and working, the next thing to test was the reading of the files, to check that they were being found, and read correctly. Of course just because testing is concentrating on a different part of the code, does not mean that the rest of the code is not being checked at the same time. All that it means is that the rest of the code is not under as much inspection as the code being tested. A lot of the tests were left in the code while other parts of the code were being tested. The reason for this was because if one part breaks, it can be useful to see what the results in the rest of the code are. This is especially useful to double check that other error checking code is being checked for as many of the range of cases as is possible. Another reason for leaving tests in during the testing of other parts of the code is because some errors are complex, and may be within the correct range for each individual part, but when the separately tested modules are all linked together the wrong output is generated. This can often be the case when the information has been manipulated in a technically correct way, but a particular sequence had an unforeseen consequence. By examining the results of the tests in the rest of the code it is often possible to locate the source of the problem, or at least where the erroneous interaction is occurring.
Full testing of the engine has occurred on several of the test machines, and the main server at http://www.YEdit.com/. This testing has involved asking people who could be interested in the engine to try it out and see what they think about it.
The first seven test subjects were asked to try out the web based co-operative authoring system, set up inside the Massey firewall, so only those that were located inside the firewall could get access to the machine. Out of those seven people asked to have a look and test the site, five visited the test web site, four filled in a simple survey to gauge their knowledge and experience of computers, and four (including the person who did not fill out a survey form) actually tried out the editing of any of the web pages. From the web server logs, it seems as though they only visited once, and then never went back. This could be because of the pressures that people face at Massey at the present time, or because they do not need the abilities of YEdit at this stage. There were a couple of comments on the forms and in the web pages about the engine. The comments that were left by this group are similar to the comments that I have received about the public site. The comments have been along two main themes the first being that the ideas for co-operative authoring are very good, and the second being that they would like an easier method of editing the web pages, rather than having to know all the HTML for a page. I learnt some valuable lessons (and information) from this testing. The idea for a simpler method for editing the web pages is one thing that will be followed up after this research is complete.
Further testing is taking place at http://www.YEdit.com/, and some limited promotion has been undertaken to let groups that could be interested in the YEdit system know that it exists. One such group is the people who visit WikiWiki (a user editable, pattern oriented web space), and I have established links from there that mention the YEdit system and provide links to http://www.YEdit.com/.
Testing at the public web site has progressed slowly, but has produced some useful results, such as discovering an unintended interaction between the last date of modification and caches between the engine and the user. This interaction never seemed to produce an error on the server side, but produced an "all Ok" error on the client side. This is a very peculiar error to get, because "all Ok" means the request succeeded and the result is provided, but in this case the "all Ok" status was somehow getting interpreted and displayed as an error, which should never happen, as it is not an error. This has since been rectified by not supplying the last modified date as part of the headers sent back with the document. The use of http://www.YEdit.com/ is slowly increasing as efforts to promote the web site are progressing. A discussion of web site promotion is beyond the topic of this thesis.
4.4.1 Creating a testbed
Testbeds were used in the creation of the YEdit system for testing changes and new ideas. The testbed web servers were fully functional web servers that were placed on local machines to test the responses of the YEdit system. The reason for using local testbed web servers was to test ideas and changes in a fully working environment before they were run live on the public web server.
Some of the reasons for creating a testbed for co-operative authoring and collaboration are to test out ideas and changes, to get a working model, to test the feasibility of concepts and to see what other people think of the ideas. Also it allows a small number of people to test and refine new ideas before they are moved to the public web server.
The testbeds were created so that YEdit system could be plugged into a web server, and it could be tested and re-written as the process continued around the iterative spiral of ideas, design through testing. Because of the development path suggested by the spiral model, the ideas, design, coding, testing, etc are all spread throughout the whole project. This means that it is important to have testbeds where the changes and new ideas can be tested and refined before they are finalised for the public web server. Effectively this means that the project has been through many phases of idea generation, design, coding and testing. Because of this various different approaches have been tried for many different parts of the project. For example, some of the early prototypes had options and directory structures hard coded into the code (as they were only there for testing ideas), and as the ideas worked, the options and directory structures were moved out to a initialisation file, in progressive steps. In the current version all the directory structures are stored in the initialisation file, along with many other options, such as method of access to the version storage area, and the classes used to access it.
The initialisation file has been further extended to generalise the features. The current version supports accessing various initialisation files, for example there may be one per person, one per application, along with ones for the system as a whole, and custom settings based on both the person and the application. This generalisation will allow the initialisation files to be used in a more general context, as well as supporting both web and non-web access to the versioning storage area.
As an example, here is a portion of the initialisation file that is specific to co-operative authoring. This is the portion that defines where the file storage, that stores the versions, is located. As can be seen in the file (Figure 8: Example portion of an initialisation file), it can store information for more than one system, which allows the same initialisation file to be used on different systems with ease. The information about the storage location is supplied with the "Collaboration.storage" option; this allows the choice of system that YEdit is currently running on. The options for this particular file are "File.YEdit" for running on the public web server or "File.localhost" for running on one of the local test web servers. As can be seen by the options below that, the option for "Collaboration.storage" is then used to select the correct file locations and code to access that location. A full example of an initialisation file is located in the appendix - Appendix A: A full example of a preference file.
##---Program wide Preferences (properties)--- ##Location = Jar:/Preference/ ##Default systems for the storage location Collaboration.storage = File.YEdit ##File system storage Collaboration.File.localhost.BaseServer = D Collaboration.File.localhost.BaseDir = \\Software\\Java\\revisions\\ Collaboration.File.YEdit.BaseDir = /usr/home/yedit/revisions/ FactoryAccess.File.localhost = com.YEdit.ServerInterface.FileSystem.FileSystem FactoryAccess.File.YEdit = com.YEdit.ServerInterface.FileSystem.FileSystem
Figure 8: Example portion of an initialisation file
The project is accessible worldwide (at http://www.YEdit.com/). The local testbeds are now used to test changes and ideas before they are put onto the public server. The local testbeds are especially useful for tests that would not be advisable to run over the Internet. These are tests like loading response (testing what happens under heavy load), and any other tests that may interfere with either the other hosts on the same machine as YEdit, or the machines in-between the two systems being tested.
4.5 Summary
The design model used for the creation of the co-operative authoring and collaboration engine was the spiral design model because the iterative model of creation and orderly refactorings, were a good match for the project.
Some other areas were looked at in the process of refining the initial idea of enhancing communication over the Web. One of the first was the presentation of information, the split between the information (content) and the display environment (context). Test prototypes were created that used this split to enable one version of the content to be used for both the text only and the graphical displays.
Another area that was looked at was multi-tiered/multi-homed web sites. This was to separate the production of information from the display of that information. This means that one web server could look after all the active content (such as returning all the information from a storage system), and another web server (either on the same machine, or preferable in a different location, with a different Internet connection) could display a copy of the active content, which has been stored in static files. This gives higher reliability, as the area that is most likely to have a problem is the active content (as there is more to go wrong), while the static web site can still display all the information up to the point of the problem. Or if the static site has a problem, all traffic can be moved to the active site.
Two areas that may look similar on the surface were looked at, BSCW/CSCW, and WebDAV which will be discussed in more detail in the following two paragraphs.
BSCW/CSCW (BSCW being the main version of CSCW for the Web) enables collaboration over the Web and is a 'shared workspace' system that supports storage and retrieval of documents and sharing information within a group. This is integrated with an event notification and group management mechanism in order to provide all users with awareness of others activities in the shared workspace. In particular BSCW is a networked support mechanism, which provides support for co-operative document creation, (for example threaded discussions, group management, search features, and more).
WebDAV is a protocol that "defines the HTTP extensions necessary to enable distributed web authoring tools to be broadly interoperable, while supporting user needs". The protocol includes some information that will be helpful for distributed authoring and versioning. It is very possible that in the future, any Web communication could use this protocol to communicate authoring and versioning information. WebDAV is a protocol, more specifically, it is an extension of HTTP/1.1, which adds new HTTP methods, and headers to the HTTP protocol, as well as how to format the request headers and bodies.
The design of the engine was such that the access to the engine, the access to the file storage system, and the interface between them were all separated out. This meant that with the middle interface linking the user and server interfaces, the user and server interfaces could be created separately, and could be changed to suit the environment that surrounds the engine. In order to create this prototype, the server interface was implemented using access to the system's file system, and the user interface was implemented using a web-based interface. The web-based interface has three main parts (Refer to Figure 4: Interaction of the main components of YEdit). The read servlet displays web pages; the browse servlet allows interaction with the information about the different versions, and access to the edit servlet. The edit servlet allows the web pages to be created and edited. The engine was created using Java servlets, as they provide a good match to the requirements of the engine.
The engine is currently working at http://www.YEdit.com/ and has had user testing both there and on test machines, as well as testing throughout the creation process.
| (3 Web Collaboration Software) Previous | Next (5 Conclusion) |