- Business Collaboration
- Business Collaboration talk
- Abstract/Contents
1 Introduction
2 Review
3 Web Collaboration Software
4 Design > Test
5 Conclusion
6 Glossary
7 Appendix
8 References
This is an archived version, please use the menu on the left, or jump to the new version: 2.00 Web review
This research is concerned with co-operative authoring of documents and collaboration about those documents, specifically over the World Wide Web. Secondary to this is whether the research can be generalised to support co-operative authoring using systems of communication other than the Web, to allow for future expansion. This purpose is supported by Berners-Lee's original intentions for the Web, which includes support for collaborative authoring and collaborative design of something other than hypertext itself. Because of this we shall therefore review the original vision that drove the development of the Web, and the Web, as it is today.
Berners-Lee initiated the creation of the Web in 1989, when he wrote and circulated for comment a project proposal [Berners-Lee 1989] for a networked Hypertext system for CERN (Conseil Européen pour la Recherche Nucléaire (French), European Organisation for Nuclear Research, now known as the European Laboratory for Particle Physics). The project proposal was based on the need to enable people to share documents, work, and ideas across groups, and allow interaction between those groups.
Although the Web has been spectacularly successful in its current form, has it really lived up to its original goals? Is the current form of the Web all that it was intended to be, or was it intended to be something more? To answer these questions, we need to go back in time to both some initial stirrings about the possible use of technology, and of course the conception of the Web by Berners-Lee in 1989, a mere eleven years ago.
2.1 The Web's first stirrings
'As we may think' [Bush 1945] details Dr. Bush's view of the future of science after the war. It details the things that scientists should work on to bring in a new age. It goes into detail about technology that we use in our everyday lives, in terms of the day. The technology that Dr. Bush mentions in this article is very forward thinking and includes things that resemble our current computers, digital cameras, mass storage of information (such as mini-hard drives, CD's, and DVD's) on small sized media, speech recognition systems, credit cards, the Web and much more.
The Timeline below was condensed primarily from the following two sources:
- "A Short History of the Web" [Cailliau 1995]
- "A Little History of the World Wide Web" [W3 1995]
Pre Web creation history (1945-1989)
| 1945 July | "As we may think" [Bush 1945], by Vannevar Bush |
| ... | |
| 1965 | The term "Hypertext" is coined by Ted Nelson |
| 1968 | The first Hypertext system is produced and demonstrated by Douglas Engelbart on the 9th December at the Fall Joint Computer Conference. Along with this, other innovations such as the mouse and shared computer screens were demonstrated. |
| ... | |
| 1979 | SGML (Standard Generalised Markup Language) is invented by Charles Goldfarm. HTML (HyperText Markup Language) is based on SGML. |
| 1980 | Berners-Lee creates "Enquire" [Berners-Lee WtW] a notebook program, "Enquire-Within-Upon-Everything", which allows links to be made between arbitrary nodes. Each node had a title, a type, and a list of bi-directional typed links. |
| 1981 | In "Literary Machines" Nelson [1981] describes a worldwide publication system ("Xanadu"). |
| 1987 | CERN and US laboratories connect to the Internet as the main means of exchanging data. |
This timeline gives some indication of the events that led up to and influenced Berners-Lee's proposal. As can be seen, there are several events that preceded Berners-Lee's proposal to create what was later named the World Wide Web (until 1990 it was named 'Mesh'). The pre-web time scale, starting from Bush's article, is considerably larger (1945-1987, 42 years) than the post-web time scale below (1989-1995, 6 years). This is because after the Web was first introduced, it picked up momentum very quickly, and has kept increasing its momentum to this day. The timeline below details some of the important steps that have led the Web to where it is at the present time.
Post Web creation history (1989-1995)
| 1989-March | First project proposal for a networked Hypertext system for CERN (the Web is born) written and circulated for comment (Berners-Lee). |
| Paper "HyperText and CERN" produced as background. | |
| 1990-September | Mike Sendall, Berners-Lee's boss, OKs the purchase of a NeXT cube processor, and allows him to go ahead. He selects "World Wide Web" as a name for the project (over Information Mesh, and others). |
| 1990-November | Initial WorldWideWeb prototype developed on the NeXT (Berners-Lee). |
| Nicola Pellow joins and starts work on a line-mode web browser. | |
| Berners-Lee gives a colloquium on hypertext in general. | |
| 1990-Christmas | Line mode and NeXTStep web browsers demonstrable. |
| Access is possible to hypertext files, CERNVM "FIND", and Usenet. | |
| 1991-May-17 | Presentation to C5 committee and general release of WWW on central CERN machines. |
| 1991-June-12 | CERN Computer Seminar on WWW. |
| 1991-August | Files available on Usenet, posted on alt.hypertext (6, 16, 19th Aug), comp.sys.next (20th), comp.text.sgml and comp.mail.multi-media (22nd). |
| 1991-October | VMS/HELP and WAIS gateways installed. |
| Mailing lists www-interest (now www-announce) and www-talk at info.cern.ch are started. | |
| One year status report. | |
| Anonymous telnet service is started. | |
| 1992 | The world has 50 web servers. |
| 1992-January-15 | Line mode web browser v1.1 is available by anonymous FTP. |
| Presentation to AIHEP'92 at La Londe. | |
| 1992-February-12 | Line mode v1.2 is announced on alt.hypertext, comp.infosystems, comp.mail.multi-media, cern.sting, comp.archives.admin, and mailing lists. |
| 1992-July | Distribution of WWW through CernLib, including Viola. WWW library code ported to DECnet. |
| Report to the Advisory Board on Computing. | |
| 1993 | 50 Web servers grows to 250. |
| The Mosaic browser is created. | |
| 1994 | 2500 Web servers. |
| 1995 | 73500 Web servers. |
| Sun creates HotJava. |
The following sums up the Web, as it was just a couple of years after it was created.
WorldWideWeb - Summary (1991-1992)The WWW project merges the techniques of networked information and hypertext to make an easy but powerful global information system.
The project represents any information accessible over the network as part of a seamless hypertext information space.
W3 was originally developed to allow information sharing within internationally dispersed teams, and the dissemination of information by support groups. Originally aimed at the High Energy Physics community, it has spread to other areas and attracted much interest in user support, resource discovery and collaborative work areas. It is currently the most advanced information system deployed on the Internet, and embraces within its data model most information in previous networked information systems.
In fact, the Web is an architecture which will also embrace any future advances in technology, including new networks, protocols, object types and data formats.
http://www.w3.org/Summary.html (Berners-Lee)
W3 Status: Historical interest
2.1.1 The Vision and Original intentions for the Web
Berners-Lee attempted to persuade CERN management that the Web was in their best interests. He detailed in this document entitled "Information Management: A Proposal" [Berners-Lee 1989] the original proposal that was the first step in the creation of the World Wide Web. It details some of the problems that CERN was having (especially information management, and tracking of large projects), and makes a proposal to create a system that was the beginnings of the Web.
The following quote shows what the Web was originally designed to be used for. It details the list of intended uses for the Web at CERN. Most of these, such as online encyclopedias, online help and documentation, major news organisations, personal homepages, and to a lesser extent collaborative work [Berners-Lee 1990] are currently being used.
Intended uses for hypertext at CERN
- General reference data (encyclopedia, etc)
- Completely centralised publishing (online help, documentation, tutorial, etc)
- More or less centralised dissemination of news which has limited life
- Collaborative authoring
- Collaborative design of something other than the hypertext itself
- Personal notebook
http://www.w3.org/DesignIssues/Uses.html (Berners-Lee)
W3 Status: W3 Archive
From a talk in 1991 and 1992 entitled "W3 Concepts" [Berners-Lee 1991], the following concepts for the Web (that follow on from the intended uses that CERN had for hypertext), were put forward at an online seminar about the World Wide Web Consortium (http://www.w3.org/).
In the talk Berners-Lee talks about universal readership that allows anyone to retrieve information from any computer that they are using at the time; rather than having to go to a specific computer in a specific location to retrieve the information. Hypertext essentially allows documents to have links in them that point to other locations (typically other documents). This allows the restriction of reading documents in a serial fashion to be removed. With the removal of this restriction, documents can have links to and from any place, allowing direct linking to appropriate information, such as indexes, bibliographies, and other media such as graphics, sound and video. Searching allows for the location of specific information by the use of an engine behind the pages; this searches for the requested information and returns the results as a web page with links to the pages that it found. The client/server model allows for distributed clients and servers that are linked together by a protocol, and creates a decentralised system so that anyone can set up a client to read information, and anyone can set up a system to serve information. Format negotiation allows the client and the server to set up formats that both understand. This gives the server the ability to serve the most appropriate information to the client, such as supplying the client with graphics that it understands, or giving the information in a language that both understand.
By the stage Berners-Lee delivered this talk, the Web had started to take off. However as is shown by the quote below, some of the main reasons for creating it had been left behind. The realisation of a good HTML editor took longer than was expected (and the quality of the output still varied widely).
The Future (1993)
The WWW initiative has taken off and become the emerging leader in Internet information systems. However, it has been overtaken by its popularity, and many of the original design goals for a collaborative tool have still not been implemented.
At the same time, it is spreads(sic) into many fields which put demands on its functionality. Fortunately, these all fit in well with the original design concepts.
Collaborative work was the original design goal of W3. This involves everyone working together in a group to be able to share knowledge, modifying, annotating, and contributing as well as reading. This is an exciting area. It requires good wysiwyg hypertext and hypermedia editors (which will probably arrive during the next year, 1994) as well as authentication of users.
http://www.w3.org/Talks/CompSem93/FutureText.html (Berners-Lee)
One of the original visions behind the Web was to provide a collaborative computing environment that provided an easy method for the exchange and storage of information and knowledge. Information and knowledge were not meant to become lost in a sea of web servers and surfers, with people struggling to find the information that they require. As the Web has grown, and outstripped other methods of accessing information over the Internet [NetValue 2000], many people form an idea that the Web is all that there is to the Internet, as that is the part that they see most often.
Looking at statistics for Internet usage as at November 2000 shows clearly that Web use is higher than other uses of the Internet. The percentage of people with Internet access that browsed the Web in past month in the USA was 97.3% and in the UK was 96%, whereas the percent of people that used email in the USA was 44.5% and in the UK was 60.6%. Usenet usage was even less at 5.1% in the USA and 10.5% in the UK.
Some of the ideas for the Web (http://www.w3.org/DesignIssues/Editor.html April 1998) were that it should be universal and be able to encompass anything, from a scribble on the back of an envelope, through to a polished work of art. It should easy to work on documents, add links, annotations, and to copy information containing embedded back links to the original document.
The Web has several key features that have helped to propel both its initial acceptance, and its growth since that time.
The simplicity of the Web's client/server design allows for ease of distributed use and development, allowing people to use it easily, regardless of location. The Web can leverage legacy technology, which means that people can still access and use legacy technology with the latest web browsers, for example Gopher [RFC1436] and WAIS [RFC1625]. The Web is platform- and operating system- independent, which means that people are free to choose the system that they want, rather than being locked into using only one system. Because the Web is based on open standards, we know that it will still be available in the future, whereas if it were proprietary, users would be locked into both the whim and success of the proprietor company. The Web standards are also portable, extensible and scaleable, which means that the standards can be adapted and changed to changing circumstance, and they will tend to have greater acceptance because as they are open and portable, there are more people that can use them.
2.2 Web interaction
Commonly the Web is used for retrieving information, and there is very little in the way of interaction between users. Information transfer over the Web is mostly one way, from the Webmaster, to the reader. There are a few techniques to make the Web more interactive.
One method is to add a section to the web site that gives people a form that they can fill in with appropriate information, and then submit it. These can be used for email feedback, for entry into guest books that appear on the page, as general comment forms that get saved into a database, or as more interactive things such as polls and visible comments on documents.
Another method of making the Web more interactive is by setting up customisation features for users. This can be done by storing information about how the user wants information presented to them, what information they want presented to them, and also whether they want to be alerted to new or changing information, for example being alerted by email when a web page changes.
A different method that is employed by a small number of web sites, such as WikiWiki [Cunningham], and its clones, is to make the whole web site editable by anyone. This opens up the whole site to being edited and changed by anyone (although it could be limited to a select group), and allows changes directly to the web pages.
In order to understand why co-operative authoring will be useful, one needs to have some understanding of the current state and sophistication of web sites. Company web sites are looked at because they have a good range of sophistication that ranges from web sites that show very little knowledge of the Internet and the Web, through to companies that use the Web to the fullest.
2.2.1 Typical current web sites
Looking at typical current web sites gives a good background to what is currently used by a reasonable proportion of web sites. This is good background because it allows one to compare the differences between the current use of the Web, and the abilities that are being proposed and implemented for the research for this thesis.
Current web sites are predominately created to serve content or to enable e-commerce for users over the Web. There are many examples of web sites with significant content that is very heavily used, such as good search engines that have a large amount of information. There are also many examples of web sites that have little in the way of content; for example many personal home pages, which just have the person's name and not much more. As there is little content, there is no compelling reason for anyone to come back (as can be seen by the low number of hits commonly displayed on their page counters).
Currently the main use of the Web is the transfer of information. This can be simply to make any information available, just in case someone might want that information (for example many personal home pages, or a simple 'Hello, this is who I am...'), or to make specific information available that the general public wishes to know (whether it is domain specific information, entertainment, or something else). The creators of web sites need to think about the information they are willing and able to give their visitors. After all, if a visitor doesn't get something from a web site (from information that they need, through to a warm fuzzy feeling, if that is what the web site has been created for), they will not come back. What's more, they will not refer other people to the web site. Many people believe "Word of mouth", is one of the most powerful forms of publicity.
Typical progression as companies discover(ed) the Web
Many companies start with little or no knowledge of either the Web or the Internet, and progress through stages as they learn more about the Internet and the Web; and realise the impact that it is possible to create with good use of these technologies.
* Individual user sites: At this stage there are just a few people in the company who are either aware of the Web, or have an idea of what can be achieved using the Web. These groups can put information onto the Web that they think would be useful and that they are familiar with. This means that there are a few sites that give a taste of the company, but they are commonly separate with few links between them, and often display duplicated information. This method of creating awareness of the company on the Web is a good start and has the potential (especially today) to quickly show positive returns, now that the Web has more awareness throughout the community.
* Brochureware: Brochureware sites are easy to distinguish from other sites because they are commonly a direct copy of a print brochure that has been scanned and placed on the Web with little or no changes made. This kind of site is very easy and cheap to create, but it is also deceptive in that it doesn't really achieve much, especially when it only contains phone numbers and no email addresses, as is common.
* Limited interaction: Limited interaction sites contain useful information about the company, products and the people that make up the company. This is probably the most common type of site. Often this is all that a company needs, especially if it is not their business to sell products. On sites such as these, there could be anywhere from just a page or two (for a small company) through to hundreds or more pages (for a larger company). There are generally different methods displayed for contacting the company, from their physical address, phone numbers, email addresses, feedback/comment forms, and sometimes other contact methods such as online chatting.
* E-Commerce: E-Commerce sites generally contain all the information that a limited interaction site contains, with the added ability to buy and sell directly from the web site. Sites that implement e-commerce have either a product or a service to sell and they are generally designed so that the process of buying and selling is the primary focus of the web site.
* Interactive and relationship building: Interactive and relationship-building sites generally focus on interactive features with the customer, and building an ongoing relationship with them. This can consist of many different ideas and processes, all of which are in place to keep the company's name and products in front of the customer as much as possible, with the customer's permission. These sites can have mailing lists, discussion pages, online chats, and many other options for the customer to interact with the company, and in the process build a higher awareness of the company in the customer's mind. These sites can also be built for companies that do not sell services or products (for example news sites) that want to ensure constant and repeat visitors, while providing them with a high quality service.
Unfortunately, not all companies that create a presence on the Web understand what the Web and the Internet are, and how they work. Typically, such companies and individuals are unaware of Netiquette, which is the social conventions that are necessary if the net is to remain a pleasant working, educational, and recreational environment. Consequently they are inclined to treat the Internet as their own exclusive resource, and abuse its ability to deliver information to millions of uninterested computer users. By abusing the power of the Internet they force others to pay for their bad marketing campaigns by sending hundreds of thousands of emails, or newsgroup postings extolling their products and services. This unfortunately is quite prolific at the moment, and it is also the most destructive. This is commonly called 'SPAM' (It got the name from the Monty Python script in which there is the repeated overuse of the product called 'Spam', a potted meat. In this script a customer comes into a shop to buy some food, and everything contains many portions of Spam, and little else. The script ends in a song that only contains the word 'Spam').
Some other common faults are:
* Web sites/pages that only have contact details to be contacted for more information. It is a better idea to supply the information on the web page along with contact details, so that people can access the information, and then follow up with contact if further contact is necessary.
* Pages that require you to fill in a form before they will post, email or otherwise contact you with information that can readily be displayed on their web page
* Pages that have a lot of fluff, and/or little or no content/information.
* Pages that are over laden with graphics or scripts (most users are connected by modem. In the USA 49.9% are connected but only 6% have a broadband connection, in the UK 31.2% are connected but only 1% have a broadband connection [NetValue 2000] and even those that do have a broadband connection, may want to see the page quickly, as they don't have the time to wait around).
* Pages that require the use of graphics/JavaScript/etc, or only display on the latest web browser (This can be annoying for the average user who is browsing, but can be discriminating for those with disabilities. For example if the web site is only accessible with graphics, a blind person can't use it. Web sites that able-bodied people have trouble accessing, can be even worse for those with disabilities).
If a company can avoid most of the common faults, it demonstrates that they have a good understanding of the Web and the people who use it. When companies have a good understanding of the Web and the people who visit their site it is much easier to create a site that will meet the needs of the visitors and entice them to come back. It is always a good sign to have most visitors as repeat visitors, as they already know the site and have an idea of whom you are which makes it easier to achieve the aim of the site. Unfortunately it is very easy to get led off in another direction by nice "eye-candy", rather than following the main aim for the site. This is bad for both web site developers, because it is unproductive work, and it is bad for the visitors, as it provides a distraction from the reason that they have come. Also another downside to "eye-candy" is that often, specific browsers and/or plug-ins are required to display it, which means that it can easily destroy the usability of the site for most other users. Generally if a company reaches this point they will have put together a small group that takes responsibility for the corporate web site, and will keep it updated and expanding. Generally when companies put a small group together to work on a web site, it is with the understanding that all changes to the web site go through that central group. This leads into the different types of models for web sites, as the One-Many model described above, is not the only model for web sites.
The common model for web sites in companies is a One-to-Many relationship (See Figure 1: Relationship models). That is, there is one person (or group) who is responsible for the web site, while there are many people viewing the site. This is in contrast to the original objective for the Web, with Many-to-Many relationships where many different people are discovering the Web and creating sites by themselves. This One-to-Many relationship is a common thread throughout companies, and has been tried and tested over a long time, and it does work, when implemented correctly.
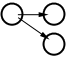
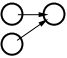
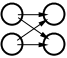
The other side of the coin, the Many-to-One aspect is commonly found as part of a larger overall site. A good example of this is where people can leave feedback for the web master, or other designated person. One other place to find Many-to-One sites is as part of a Many-to-Many site, where there are people working together on a project. As part of their site they have information that is appropriate for a manager, or other people further up the chain of command. This type of site allows collaboration between group members who will commonly use many other methods to collaborate, rather than just the Web. The web site is likely to be a small part of the collaboration process.
2.3 Summary
Many people now think that the Web is all that there is to the Internet, and many think that the Web is the Internet. Because the Web has taken off, and become the main activity on the Internet [NetValue 2000] (compared with FTP, email, etc), its popularity has overshadowed the fact that there is a lot more to the Internet than the Web application that runs over the Internet. There are another two reasons why the Web has seemed to overtake other applications on the Internet. The first is that almost all web browsers support connections to other Internet protocols, such as GOPHER, WAIS, and FTP, as well as supporting other common Internet standards, such as Email, and Usenet (Newsgroups). The second significant reason that the Web is seen to be the most popular part of the Internet is that it is very visible, and has had a lot of publicity to actively promote it. Other equally important parts of the Internet, running as server programs and applications, are invisible to most users. The hidden side of the Internet is seldom seen because it provides the infrastructure that runs everything, rather than the flashy applications that people use. It is this infrastructure that provides the common connections, protocols, and systems that the user applications rely on.
Berners-Lee created the Web in 1989 to enable people to share work and ideas in an easy-to-use form. It was based on ideas and developments dating back to at least 1945 with Vannevar Bush's article 'As we may think' published in the Atlantic Monthly in July 1945.
Since 1989 the Web has come a long way in terms of publishing information and one-way communication. Unfortunately, in this process only some ideas have been pushed forward, and some ideas like the idea of co-operative authoring and collaboration, which was one of the cornerstones of its creation, have not progressed very well.
Currently there are some options available for collaboration on documents over the Web, but most of them rely on all authors using the same editing program, or they are limited to a specific domain of use. There are some web based document collaboration sites, but these are limited to a specific domain, and require the use of specific notation and are good for the niche that they inhabit. Currently the options for full and open co-operative authoring (including creation of web sites) are very limited, especially with regard to the packages that can be used.
| (1 Introduction) Previous | Next (3 Web Collaboration Software) |